
In Part 3 of this series, I focused on preparing a dataset for training a language model, combining multiple books into a corpus, tokenizing with tiktoken, and creating PyTorch datasets. With the data pipeline in place, the next step in building a GPT-style model is to understand attention mechanisms.
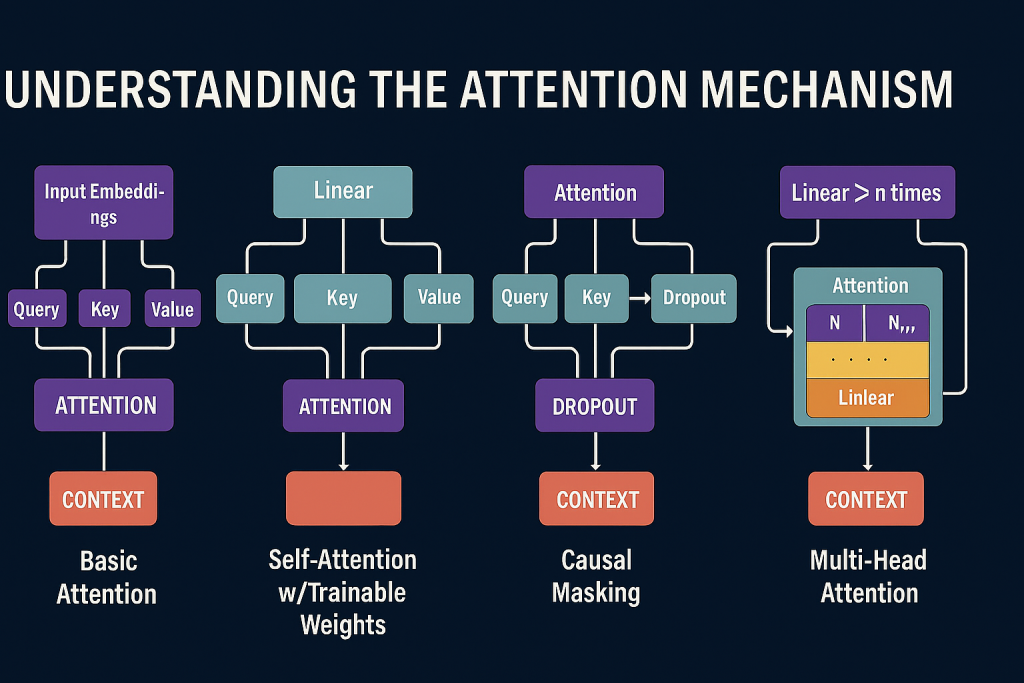
Attention is the core innovation behind transformers. It allows models to dynamically focus on different parts of an input sequence, capturing dependencies across long contexts without recurrence. In this post, I will walk through my journey of implementing attention in PyTorch, starting from the most basic dot-product attention without trainable weights, and building up to a reusable multi-head attention module.
Why Attention?
Traditional sequence models like RNNs and LSTMs process tokens step by step, which makes it difficult to capture long-range dependencies. Attention solves this by allowing every token to directly interact with every other token in the sequence. The mechanism is built around three concepts:
- Query (Q): What we are looking for.
- Key (K): What each token offers.
- Value (V): The information carried by each token.
By comparing queries with keys, we compute attention scores that determine how much weight to give each value when forming a context vector.
Step 1: Basic Attention Without Trainable Weights
I began with a simple example: computing attention scores using dot products between a query and embeddings. This helped me understand the mechanics before adding trainable parameters.
example_input_embeddings = torch.tensor([
[0.23, 0.87, 0.45],
[0.12, 0.76, 0.34],
[0.98, 0.54, 0.21],
[0.67, 0.39, 0.88],
[0.53, 0.29, 0.74],
[0.41, 0.65, 0.32]
])
print(example_input_embeddings.shape)
example_query = example_input_embeddings[1]
example_attention_scores = torch.empty(example_input_embeddings.shape[0])
for i, embedding in enumerate(example_input_embeddings):
example_attention_scores[i] = torch.dot(example_query, embedding)
print(f"Example attention scores for 2nd query: {example_attention_scores}")This produces raw attention scores, which are then normalized with softmax to form probability-like weights.
normalized_example_attention_scores = torch.softmax(example_attention_scores, dim = 0)
print(f"Normalized attention scores for 2nd query: {normalized_example_attention_scores}")Finally, the context vector is computed as a weighted sum of embeddings:
example_context_vector = torch.zeros(example_query.shape)
for i, embedding in enumerate(example_input_embeddings):
example_context_vector += normalized_example_attention_scores[i] * embedding
print(f"Context vector for 2nd query: {example_context_vector}")This completes the simplest form of attention.
Step 2: Scaling Up with Matrix Multiplication
Instead of computing scores with loops, we can use matrix multiplication to calculate all pairwise attention scores efficiently:
all_attention_scores = example_input_embeddings @ example_input_embeddings.T
print(f"All attention scores using matrix multiplication:\n {all_attention_scores}")Applying softmax row-wise normalizes the scores for each query:
all_normalized_attention_scores = torch.softmax(all_attention_scores, dim = -1)
print(f"All normalized attention scores:\n {all_normalized_attention_scores}")And context vectors for all queries can be computed in parallel:
all_example_context_vectors = all_normalized_attention_scores @ example_input_embeddings
print(f"All context vectors using matrix multiplication:\n {all_example_context_vectors}")This is the foundation of self-attention.
Step 3: Introducing Trainable Projections
In transformers, queries, keys, and values are not just the raw embeddings. They are learned projections. Using linear transformations, each input embedding is mapped into Q, K, and V spaces.
example_input = example_input_embeddings[1]
input_dim = example_input_embeddings.shape[1]
output_dim = 2
torch.manual_seed(246)
weight_query = torch.nn.Parameter(torch.rand(input_dim, output_dim), requires_grad = True)
weight_key = torch.nn.Parameter(torch.rand(input_dim, output_dim), requires_grad = True)
weight_value = torch.nn.Parameter(torch.rand(input_dim, output_dim), requires_grad = True)
example_query = example_input @ weight_query
example_key = example_input @ weight_key
example_value = example_input @ weight_valueThis step introduces trainable parameters, allowing the model to learn how best to represent tokens for attention.
Step 4: Building a Self-Attention Module
To make attention reusable, I wrapped it in a PyTorch module. This encapsulates the entire process: projecting Q, K, V, computing scores, applying scaling and softmax, and generating context vectors.
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.weight_query = nn.Parameter(torch.rand(input_dim, output_dim))
self.weight_key = nn.Parameter(torch.rand(input_dim, output_dim))
self.weight_value = nn.Parameter(torch.rand(input_dim, output_dim))
def forward(self, x):
queries = x @ self.weight_query
keys = x @ self.weight_key
values = x @ self.weight_value
attention_scores = queries @ keys.T
scaling_factor = keys.shape[-1] ** 0.5
attention_weights = torch.softmax(attention_scores / scaling_factor, dim = -1)
context_vector = attention_weights @ values
return context_vectorUsing this module:
torch.manual_seed(246)
self_attention = SelfAttention(input_dim, output_dim)
context_vectors = self_attention(example_input_embeddings)
print(f"Context vectors from SelfAttention module:\n {context_vectors}")Step 5: Enhancements: Linear Layers, Causal Masking, Dropout
I then extended the module to use nn.Linear layers with optional bias (SelfAttentionv2), added causal masking to prevent tokens from attending to the future, and applied dropout for regularization. These are critical for autoregressive models like GPT.
Causal masking ensures that predictions at position t only depend on tokens up to t. Dropout helps prevent overfitting by randomly zeroing out attention weights during training.
Step 6: Multi-Head Attention
Finally, I implemented multi-head attention, where multiple attention heads run in parallel, each learning different relationships. Their outputs are concatenated and projected back to the model dimension.
class MultiHeadAttention(nn.Module):
def __init__(self, input_dim, output_dim, dropout, context_length, num_heads, qkv_bias = False):
super().__init__()
assert output_dim % num_heads == 0, "Output dimension must be divisible by number of heads"
self.output_dim = output_dim
self.num_heads = num_heads
self.head_dim = output_dim // num_heads
self.weight_query = nn.Linear(input_dim, output_dim, qkv_bias)
self.weight_key = nn.Linear(input_dim, output_dim, qkv_bias)
self.weight_value = nn.Linear(input_dim, output_dim, qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer("causal_mask", torch.triu(torch.ones(context_length, context_length), diagonal = 1))
self.output_projection = nn.Linear(output_dim, output_dim)
def forward(self, x):
batch_size, num_tokens, _ = x.shape
queries = self.weight_query(x).view(batch_size, num_tokens, self.num_heads, self.head_dim).transpose(1,2)
keys = self.weight_key(x).view(batch_size, num_tokens, self.num_heads, self.head_dim).transpose(1,2)
values = self.weight_value(x).view(batch_size, num_tokens, self.num_heads, self.head_dim).transpose(1,2)
attention_scores = queries @ keys.transpose(2,3)
attention_scores.masked_fill_(self.causal_mask.bool()[:num_tokens, :num_tokens], -torch.inf)
attention_weights = torch.softmax(attention_scores / keys.shape[-1]**0.5, dim = -1)
attention_weights = self.dropout(attention_weights)
context_vectors = self.output_projection((attention_weights @ values).transpose(1,2).contiguous().view(batch_size, num_tokens, self.output_dim))
return context_vectorsThis is the same mechanism used in GPT and other transformer models.
Lessons Learned
- Starting with simple dot products clarified the mechanics of attention.
- Softmax normalization is essential for interpretability and stability.
- Linear projections allow the model to learn flexible Q, K, V representations.
- Causal masking is critical for autoregressive tasks like language modeling.
- Multi‑head attention provides richer sequence representations by letting the model attend to different aspects of the input in parallel.
- Wrapping attention into modular PyTorch classes makes it reusable and easy to extend into full transformer blocks.
Try It Yourself
The full notebook with all the steps, from basic attention to multi‑head attention, is available here:
👉 Attention Mechanisms Repository
Clone the repo, open the Jupyter notebook, and step through the code. You can experiment with different numbers of heads, embedding dimensions, and masking strategies to see how they affect the outputs.
Build It Yourself
If you want to try building it yourself, you can find the complete code with detailed explanations of each block in the source code section at the end of this post. All the best!
What’s Next
With attention mechanisms implemented, the next step is to assemble the transformer block itself. In Part 5, I’ll combine multi‑head attention with feed‑forward layers, residual connections, and normalization to build the backbone of a GPT‑style model. From there, we’ll be ready to start stacking blocks and training a small‑scale transformer.
Source Code
import torch
Example: Calculating Attention Scores with PyTorch¶
This example demonstrates how to compute attention scores using PyTorch tensors. The process involves the following steps:
Create Example Input Embeddings
- A tensor named
example_input_embeddingsis defined with 6 vectors, each of dimension 3. - All values are between 0 and 1, representing normalized embedding features.
- A tensor named
Select a Query Vector
- The second vector (index 1) from the embeddings is chosen as the query (
example_query).
- The second vector (index 1) from the embeddings is chosen as the query (
Compute Attention Scores
- An empty tensor
example_attention_scoresis created to store the attention scores for each embedding. - For each embedding vector, the dot product with the query vector is calculated and stored in the attention scores tensor.
- An empty tensor
Print Results
- The shape of the input embeddings tensor is printed to confirm its dimensions.
- The computed attention scores for the query are printed, showing how similar each embedding is to the query vector.
This approach is a simplified version of the attention mechanism commonly used in neural networks, such as Transformers, where attention scores determine the relevance of other tokens to a given query token.
example_input_embeddings = torch.tensor([
[0.23, 0.87, 0.45],
[0.12, 0.76, 0.34],
[0.98, 0.54, 0.21],
[0.67, 0.39, 0.88],
[0.53, 0.29, 0.74],
[0.41, 0.65, 0.32]
])
print(example_input_embeddings.shape)
example_query = example_input_embeddings[1]
example_attention_scores = torch.empty(example_input_embeddings.shape[0])
for i, embedding in enumerate(example_input_embeddings):
example_attention_scores[i] = torch.dot(example_query, embedding)
print(f"Example attention scores for 2nd query: {example_attention_scores}")
torch.Size([6, 3]) Example attention scores for 2nd query: tensor([0.8418, 0.7076, 0.5994, 0.6760, 0.5356, 0.6520])
Softmax Normalization of Attention Scores¶
After calculating the raw attention scores for the query vector, it is important to normalize these scores so they can be interpreted as probabilities. This is achieved using the softmax function:
Purpose of Softmax
- The softmax function transforms the raw attention scores into a probability distribution.
- Each score is exponentiated and divided by the sum of all exponentiated scores, ensuring all values are between 0 and 1 and sum to 1.
Application in Attention Mechanisms
- In neural network models like Transformers, softmax normalization is used to weigh the importance of each token (or embedding) relative to the query.
- Higher normalized scores indicate greater relevance to the query vector.
Code Explanation
torch.softmax(example_attention_scores, dim=0)computes the softmax across all attention scores.- The result,
normalized_example_attention_scores, contains the normalized weights for each embedding. - These weights can be used to compute a weighted sum of the input embeddings, focusing on the most relevant ones.
Output
- The normalized attention scores are printed, showing the probability-like weights for each embedding with respect to the query.
This normalization step is essential for interpreting attention scores and for further processing in attention-based models.
normalized_example_attention_scores = torch.softmax(example_attention_scores, dim = 0)
print(f"Normalized attention scores for 2nd query: {normalized_example_attention_scores}")
Normalized attention scores for 2nd query: tensor([0.1972, 0.1725, 0.1548, 0.1671, 0.1452, 0.1631])
Computing the Context Vector Using Attention Weights¶
After normalizing the attention scores, the next step is to compute the context vector. This vector represents a weighted sum of all input embeddings, where the weights are the normalized attention scores:
Purpose of the Context Vector
- The context vector aggregates information from all input embeddings, emphasizing those most relevant to the query.
- In attention-based models, this vector is used to provide focused information for downstream tasks, such as prediction or decoding.
Calculation Steps
- Initialize a zero vector with the same shape as the query vector.
- For each embedding, multiply it by its corresponding normalized attention score.
- Sum all weighted embeddings to obtain the final context vector.
Code Explanation
example_context_vector = torch.zeros(example_query.shape)initializes the context vector.- The loop iterates over each embedding and its attention weight, accumulating the weighted sum.
- The result is printed, showing the context vector for the selected query.
Interpretation
- The context vector reflects the most relevant features from the input embeddings, as determined by the attention mechanism.
- This process is fundamental in models like Transformers, where context vectors are used to capture relationships between tokens.
This step completes the basic attention mechanism, demonstrating how queries, attention scores, and context vectors interact in neural network models.
example_context_vector = torch.zeros(example_query.shape)
for i, embedding in enumerate(example_input_embeddings):
example_context_vector += normalized_example_attention_scores[i] * embedding
print(f"Context vector for 2nd query: {example_context_vector}")
Context vector for 2nd query: tensor([0.4736, 0.5996, 0.4866])
Calculating Attention Scores for All Queries and Embeddings¶
This cell extends the attention mechanism by computing attention scores for every possible query-embedding pair in the input tensor:
Purpose of Pairwise Attention Scores
- Instead of using a single query, this approach calculates the attention score for each query vector against every embedding vector.
- The result is a matrix where each row corresponds to a query and each column to an embedding.
Calculation Steps
- Initialize an empty matrix
all_attention_scoreswith shape[num_queries, num_embeddings]. - For each query (row), iterate over all embeddings (columns) and compute the dot product.
- Store the result in the corresponding position in the matrix.
- Initialize an empty matrix
Code Explanation
- The outer loop iterates over each query vector in
example_input_embeddings. - The inner loop iterates over each embedding vector.
torch.dot(query, embedding)computes the similarity between the query and embedding.- The resulting matrix is printed, showing all pairwise attention scores.
- The outer loop iterates over each query vector in
Interpretation
- The attention score matrix provides a comprehensive view of how each query relates to every embedding.
- In multi-head attention and Transformer models, similar matrices are used to determine the influence of all tokens on each other.
This step demonstrates the generalization of the attention mechanism to all query-embedding pairs, which is fundamental in self-attention architectures.
all_attention_scores = torch.empty(example_input_embeddings.shape[0], example_input_embeddings.shape[0])
for i, query in enumerate(example_input_embeddings):
for j, embedding in enumerate(example_input_embeddings):
all_attention_scores[i,j] = torch.dot(query, embedding)
print(f"All attention scores using for loops:\n {all_attention_scores}")
All attention scores using for loops:
tensor([[1.0123, 0.8418, 0.7897, 0.8894, 0.7072, 0.8038],
[0.8418, 0.7076, 0.5994, 0.6760, 0.5356, 0.6520],
[0.7897, 0.5994, 1.2961, 1.0520, 0.8314, 0.8200],
[0.8894, 0.6760, 1.0520, 1.3754, 1.1194, 0.8098],
[0.7072, 0.5356, 0.8314, 1.1194, 0.9126, 0.6426],
[0.8038, 0.6520, 0.8200, 0.8098, 0.6426, 0.6930]])
Matrix Multiplication for Attention Scores: Why and How¶
This cell uses matrix multiplication to efficiently compute all pairwise attention scores between input embeddings. Here’s a detailed breakdown:
Why Use Matrix Multiplication?
- Matrix multiplication is much faster and more scalable than using nested loops, especially for large datasets.
- It leverages optimized linear algebra routines and hardware acceleration (e.g., GPUs), making it the standard approach in deep learning frameworks.
How Does It Work?
- The operation
example_input_embeddings @ example_input_embeddings.Tmultiplies the input matrix by its transpose. - Each entry $(i, j)$ in the resulting matrix is the dot product between the $i$-th query and the $j$-th embedding.
- This produces a square matrix where rows represent queries and columns represent embeddings.
- The operation
Code Explanation
@is the matrix multiplication operator in PyTorch (equivalent totorch.matmul).- The result,
all_attention_scores, contains all possible query-embedding dot products. - The matrix is printed to show the computed attention scores.
Relation to Transformers
- In Transformer models, self-attention is computed using similar matrix multiplication operations to efficiently process entire sequences in parallel.
- This enables the model to capture relationships between all tokens in the input.
This cell demonstrates the practical and theoretical advantages of matrix multiplication for attention mechanisms in modern neural networks.
all_attention_scores = example_input_embeddings @ example_input_embeddings.T
print(f"All attention scores using matrix multiplication:\n {all_attention_scores}")
All attention scores using matrix multiplication:
tensor([[1.0123, 0.8418, 0.7897, 0.8894, 0.7072, 0.8038],
[0.8418, 0.7076, 0.5994, 0.6760, 0.5356, 0.6520],
[0.7897, 0.5994, 1.2961, 1.0520, 0.8314, 0.8200],
[0.8894, 0.6760, 1.0520, 1.3754, 1.1194, 0.8098],
[0.7072, 0.5356, 0.8314, 1.1194, 0.9126, 0.6426],
[0.8038, 0.6520, 0.8200, 0.8098, 0.6426, 0.6930]])
Softmax Normalization of All Attention Scores¶
This cell applies the softmax function to the entire attention score matrix, normalizing each row so that the scores for each query sum to 1:
Purpose of Row-wise Softmax
- The softmax function is applied along the last dimension (columns) of the attention score matrix.
- For each query (row), the attention scores across all embeddings are converted into a probability distribution.
- This allows each query to “attend” to all embeddings with weights that sum to 1.
Calculation Steps
torch.softmax(all_attention_scores, dim=-1)computes the softmax for each row of the matrix.- The result,
all_normalized_attention_scores, is a matrix of the same shape, where each row contains normalized attention weights for the corresponding query.
Code Explanation
- The softmax operation ensures that for each query, the attention weights are interpretable as probabilities.
- The normalized matrix is printed, showing how each query distributes its attention across all embeddings.
Interpretation
- This step generalizes the normalization process to all queries, as is done in self-attention mechanisms in models like Transformers.
- The resulting matrix is fundamental for computing context vectors for every query, enabling parallel processing and richer representations.
This operation is essential for multi-query attention, allowing each token or embedding to focus on the most relevant parts of the input sequence.
all_normalized_attention_scores = torch.softmax(all_attention_scores, dim = -1)
print(f"All normalized attention scores:\n {all_normalized_attention_scores}")
All normalized attention scores:
tensor([[0.1970, 0.1661, 0.1577, 0.1742, 0.1452, 0.1599],
[0.1972, 0.1725, 0.1548, 0.1671, 0.1452, 0.1631],
[0.1458, 0.1205, 0.2419, 0.1895, 0.1520, 0.1503],
[0.1472, 0.1189, 0.1732, 0.2394, 0.1853, 0.1360],
[0.1504, 0.1267, 0.1703, 0.2271, 0.1847, 0.1410],
[0.1777, 0.1527, 0.1806, 0.1788, 0.1512, 0.1591]])
Computing All Context Vectors Using Matrix Multiplication¶
This cell demonstrates how to efficiently compute context vectors for all queries in parallel using matrix multiplication:
Purpose of Context Vectors for All Queries
- In self-attention mechanisms, each query (token) receives a context vector that summarizes relevant information from all embeddings, weighted by attention scores.
- Calculating all context vectors at once enables efficient processing of entire sequences.
Calculation Steps
- The normalized attention score matrix (
all_normalized_attention_scores) is multiplied by the input embeddings matrix (example_input_embeddings). - This operation computes a weighted sum of embeddings for each query, resulting in a matrix where each row is the context vector for a query.
- The normalized attention score matrix (
Code Explanation
all_example_context_vectors = all_normalized_attention_scores @ example_input_embeddingsperforms the matrix multiplication.- Each row in the result corresponds to the context vector for a specific query.
- The context vectors are printed to show the output for all queries.
Interpretation
- This approach is highly efficient and is used in Transformer models to compute context vectors for all tokens in parallel.
- The resulting context vectors capture the relationships and dependencies between all tokens in the input sequence.
This cell completes the demonstration of self-attention, showing how attention weights and matrix multiplication are used to aggregate information for every query in a sequence.
all_example_context_vectors = all_normalized_attention_scores @ example_input_embeddings
print(f"All context vectors using matrix multiplication:\n {all_example_context_vectors}")
All context vectors using matrix multiplication:
tensor([[0.4790, 0.5967, 0.4901],
[0.4736, 0.5996, 0.4866],
[0.5542, 0.5647, 0.4847],
[0.5322, 0.5475, 0.5343],
[0.5244, 0.5528, 0.5281],
[0.5013, 0.5851, 0.4899]])
Linear Projections for Query, Key, and Value Vectors¶
This cell demonstrates how to create query, key, and value vectors from an input embedding using learnable linear projections, a core concept in the Transformer architecture:
Purpose of Linear Projections
- In attention mechanisms, each input embedding is transformed into three distinct vectors: query, key, and value.
- These vectors are used to compute attention scores and aggregate information from other tokens.
Calculation Steps
- The input embedding is selected (here, the second embedding vector).
- The input and output dimensions are defined for the projections.
- Random weight matrices for query, key, and value are initialized as learnable parameters.
- The input embedding is multiplied by each weight matrix to produce the query, key, and value vectors.
Code Explanation
weight_query,weight_key, andweight_valueare randomly initialized matrices with shape[input_dim, output_dim].- The input embedding is projected using matrix multiplication:
example_query = example_input @ weight_queryexample_key = example_input @ weight_keyexample_value = example_input @ weight_value
- The resulting vectors are printed for inspection.
Interpretation
- These linear projections allow the model to learn how to best represent each token for the attention mechanism.
- The query and key vectors are used to compute attention scores, while the value vector is used to aggregate information.
- This process is repeated for every token in the input sequence in actual Transformer models.
This cell illustrates the foundational step of generating query, key, and value vectors, enabling flexible and powerful attention computations in deep learning models.
example_input = example_input_embeddings[1]
print(f"Example input: {example_input}")
input_dim = example_input_embeddings.shape[1]
output_dim = 2
print(f"Input dimension: {input_dim}")
print(f"Output dimension: {output_dim}")
torch.manual_seed(246)
weight_query = torch.nn.Parameter(torch.rand(input_dim, output_dim), requires_grad = True)
weight_key = torch.nn.Parameter(torch.rand(input_dim, output_dim), requires_grad = True)
weight_value = torch.nn.Parameter(torch.rand(input_dim, output_dim), requires_grad = True)
print(f"Weight query: {weight_query}")
print(f"Weight key: {weight_key}")
print(f"Weight value: {weight_value}")
example_query = example_input @ weight_query
example_key = example_input @ weight_key
example_value = example_input @ weight_value
print(f"Example query: {example_query}")
print(f"Example key: {example_key}")
print(f"Example value: {example_value}")
Example input: tensor([0.1200, 0.7600, 0.3400])
Input dimension: 3
Output dimension: 2
Weight query: Parameter containing:
tensor([[0.7902, 0.9813],
[0.5914, 0.3650],
[0.7470, 0.6896]], requires_grad=True)
Weight key: Parameter containing:
tensor([[0.8815, 0.7708],
[0.7810, 0.2139],
[0.1007, 0.5230]], requires_grad=True)
Weight value: Parameter containing:
tensor([[0.3128, 0.8854],
[0.6202, 0.9351],
[0.4072, 0.3055]], requires_grad=True)
Example query: tensor([0.7983, 0.6296], grad_fn=<SqueezeBackward4>)
Example key: tensor([0.7335, 0.4328], grad_fn=<SqueezeBackward4>)
Example value: tensor([0.6473, 0.9208], grad_fn=<SqueezeBackward4>)
Generating Keys and Values for All Embeddings & Computing Attention Scores¶
This cell shows how to project all input embeddings into key and value spaces, and how to compute attention scores using the query and keys:
Purpose of Key and Value Projections
- Each input embedding is transformed into a key and a value vector using learned weight matrices.
- Keys are used to measure similarity with queries, while values are used to aggregate information.
Calculation Steps
- All input embeddings are projected into key and value spaces using matrix multiplication:
keys = example_input_embeddings @ weight_keyvalues = example_input_embeddings @ weight_value
- The shapes and contents of the keys and values are printed for inspection.
- All input embeddings are projected into key and value spaces using matrix multiplication:
Computing Attention Scores
- The attention score between the query and the 2nd key is computed using the dot product:
example_attention_score = example_query.dot(example_key)
- All attention scores for the query against all keys are computed using matrix multiplication:
all_attention_scores_example_query = example_query @ keys.T
- These scores indicate how much focus the query should place on each value.
- The attention score between the query and the 2nd key is computed using the dot product:
Interpretation
- This process is central to the attention mechanism: queries are compared to keys to produce attention scores, which are then used to weight the values.
- In Transformer models, this enables each token to attend to all others in the sequence, capturing complex dependencies.
This cell demonstrates the mechanics of projecting embeddings and computing attention scores, forming the basis for weighted aggregation in attention-based neural networks.
keys = example_input_embeddings @ weight_key
values = example_input_embeddings @ weight_value
print(f"Shape of keys: {keys.shape}")
print(f"Keys: {keys}")
print(f"Shape of values: {values.shape}")
print(f"Values: {values}")
example_key = keys[1]
example_attention_score = example_query.dot(example_key)
print(f"Attention score for 2nd query and 2nd key: {example_attention_score}")
all_attention_scores_example_query = example_query @ keys.T
print(f"All attention scores for 2nd query: {all_attention_scores_example_query}")
Shape of keys: torch.Size([6, 2])
Keys: tensor([[0.9275, 0.5987],
[0.7335, 0.4328],
[1.3067, 0.9807],
[0.9838, 1.0601],
[0.7682, 0.8576],
[0.9013, 0.6224]], grad_fn=<MmBackward0>)
Shape of values: torch.Size([6, 2])
Values: tensor([[0.7948, 1.1547],
[0.6473, 0.9208],
[0.7269, 1.4368],
[0.8098, 1.2268],
[0.6469, 0.9665],
[0.6617, 1.0686]], grad_fn=<MmBackward0>)
Attention score for 2nd query and 2nd key: 0.8580945730209351
All attention scores for 2nd query: tensor([1.1173, 0.8581, 1.6606, 1.4528, 1.1532, 1.1113],
grad_fn=<SqueezeBackward4>)
Scaled Dot-Product Attention Weights for a Query¶
This cell demonstrates how to compute attention weights for a query using the scaled dot-product attention mechanism, a key component of Transformer models:
Purpose of Scaling
- The dot products between the query and keys can become large for high-dimensional vectors, leading to small gradients after softmax.
- To address this, the dot products are scaled by the square root of the key dimension, stabilizing training and improving performance.
Calculation Steps
- The dimension of the key vectors is determined:
keys_dim = keys.shape[-1]. - The scaling factor is computed as the square root of the key dimension:
scaling_factor = keys_dim ** 0.5. - The attention scores for the query are divided by the scaling factor before applying softmax:
all_attention_weights_example_query = torch.softmax(all_attention_scores_example_query / scaling_factor, dim = -1)
- The resulting attention weights are printed.
- The dimension of the key vectors is determined:
Code Explanation
- The scaled dot-product is a standard technique in attention mechanisms to prevent extremely sharp or flat softmax outputs.
- The softmax function converts the scaled scores into a probability distribution over all keys.
Interpretation
- The attention weights indicate how much focus the query should place on each value in the sequence.
- This scaling step is essential for effective learning in deep models and is used in every attention layer of the Transformer architecture.
This cell illustrates the mathematical refinement of attention mechanisms, ensuring stable and interpretable attention weights for each query.
keys_dim = keys.shape[-1]
scaling_factor = keys_dim ** 0.5
all_attention_weights_example_query = torch.softmax(all_attention_scores_example_query / scaling_factor, dim = -1)
print(f"All attention weights for 2nd query: {all_attention_weights_example_query}")
All attention weights for 2nd query: tensor([0.1517, 0.1263, 0.2228, 0.1924, 0.1556, 0.1511],
grad_fn=<SoftmaxBackward0>)
Computing the Context Vector for a Query Using Attention Weights¶
This cell demonstrates how to use attention weights to compute the context vector for a query, which is the final output of the attention mechanism for that query:
Purpose of the Context Vector
- The context vector summarizes information from all value vectors, weighted by the attention scores for the query.
- It allows the model to focus on the most relevant parts of the input sequence for each query.
Calculation Steps
- The attention weights for the query are multiplied by the value vectors using matrix multiplication:
context_vector_example_query = all_attention_weights_example_query @ values
- The resulting context vector is printed.
- The attention weights for the query are multiplied by the value vectors using matrix multiplication:
Code Explanation
- The attention weights (a 1D tensor) are used to compute a weighted sum of the value vectors (a 2D tensor).
- The output is a single context vector for the query, with the same dimension as the value vectors.
Interpretation
- The context vector contains the most relevant information for the query, as determined by the attention mechanism.
- In Transformer models, context vectors are used as inputs to subsequent layers, enabling the model to capture complex relationships and dependencies.
This cell completes the demonstration of scaled dot-product attention for a single query, showing how attention weights are used to aggregate information from the sequence.
context_vector_example_query = all_attention_weights_example_query @ values
print(f"Context vector for 2nd query: {context_vector_example_query}")
Context vector for 2nd query: tensor([0.7208, 1.1596], grad_fn=<SqueezeBackward4>)
Implementing Self-Attention as a PyTorch Module¶
This cell defines a reusable PyTorch module for self-attention, encapsulating the entire attention mechanism in a single class:
Purpose of the SelfAttention Module
- The module provides a flexible and reusable implementation of self-attention, suitable for integration into larger neural network architectures.
- It abstracts the steps of projecting queries, keys, and values, computing attention scores, normalizing them, and aggregating context vectors.
Class Structure
- The class inherits from
nn.Module, making it compatible with PyTorch’s model and training ecosystem. - The constructor (
__init__) initializes learnable parameters for query, key, and value projections. - The
forwardmethod implements the self-attention computation.
- The class inherits from
Forward Pass Steps
- Input tensor
xis projected into queries, keys, and values using matrix multiplication with the respective weights. - Attention scores are computed as the dot product between queries and keys.
- Scores are scaled by the square root of the key dimension to stabilize gradients.
- Softmax is applied to obtain attention weights, which are then used to compute the context vectors as a weighted sum of values.
- The context vectors are returned as output.
- Input tensor
Interpretation and Usage
- This module can be used as a building block in Transformer models and other architectures requiring self-attention.
- It demonstrates how the attention mechanism can be implemented efficiently and flexibly in PyTorch.
This cell completes the transition from manual attention calculations to a modular, trainable self-attention layer, ready for use in deep learning pipelines.
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.weight_query = nn.Parameter(torch.rand(input_dim, output_dim))
self.weight_key = nn.Parameter(torch.rand(input_dim, output_dim))
self.weight_value = nn.Parameter(torch.rand(input_dim, output_dim))
def forward(self, x):
queries = x @ self.weight_query
keys = x @ self.weight_key
values = x @ self.weight_value
attention_scores = queries @ keys.T
scaling_factor = keys.shape[-1] ** 0.5
attention_weights = torch.softmax(attention_scores / scaling_factor, dim = -1)
context_vector = attention_weights @ values
return context_vector
Using the SelfAttention Module to Compute Context Vectors¶
This cell demonstrates how to instantiate and use the custom SelfAttention PyTorch module to compute context vectors for a batch of input embeddings:
Purpose of the Example
- Shows how to apply the self-attention mechanism to a set of input embeddings using a modular, trainable layer.
- Illustrates the integration of the
SelfAttentionclass into a typical PyTorch workflow.
Calculation Steps
- The random seed is set for reproducibility of the weight initialization.
- An instance of
SelfAttentionis created with specified input and output dimensions. - The module is called with the input embeddings, producing context vectors for each input.
- The resulting context vectors are printed for inspection.
Code Explanation
self_attention = SelfAttention(input_dim, output_dim)creates the attention layer.context_vectors = self_attention(example_input_embeddings)applies the layer to the input data.- The output,
context_vectors, contains the aggregated information for each input embedding, as determined by the attention mechanism.
Interpretation
- This example demonstrates the practical use of a self-attention layer, as found in Transformer models and other deep learning architectures.
- The context vectors can be used for further processing, such as classification, sequence modeling, or as input to additional network layers.
This cell completes the end-to-end demonstration of self-attention, from manual calculations to modular implementation and application in PyTorch.
torch.manual_seed(246)
self_attention = SelfAttention(input_dim, output_dim)
context_vectors = self_attention(example_input_embeddings)
print(f"Context vectors from SelfAttention module:\n {context_vectors}")
Context vectors from SelfAttention module:
tensor([[0.7227, 1.1697],
[0.7208, 1.1596],
[0.7256, 1.1836],
[0.7266, 1.1898],
[0.7245, 1.1777],
[0.7225, 1.1676]], grad_fn=<MmBackward0>)
Self-Attention Module with Linear Layers and Optional Bias¶
This cell defines an enhanced version of the self-attention module using PyTorch’s nn.Linear layers for query, key, and value projections, and introduces an option to include bias terms:
Purpose of the Enhanced Module
- Uses
nn.Linearlayers for projections, which are standard in deep learning and support bias terms for added flexibility. - The
qkv_biasparameter allows toggling bias in the query, key, and value projections.
- Uses
Class Structure
- Inherits from
nn.Modulefor compatibility with PyTorch’s model ecosystem. - The constructor initializes three linear layers for query, key, and value projections, with optional bias.
- The
forwardmethod implements the self-attention computation.
- Inherits from
Forward Pass Steps
- Input tensor
xis projected into queries, keys, and values using the respective linear layers. - Attention scores are computed as the dot product between queries and keys.
- Scores are scaled by the square root of the key dimension to stabilize gradients.
- Softmax is applied to obtain attention weights, which are then used to compute the context vectors as a weighted sum of values.
- The context vectors are returned as output.
- Input tensor
Interpretation and Usage
- This module is more flexible and closer to real-world Transformer implementations, which often use linear layers with bias.
- The bias terms can help the model learn more expressive representations, especially in complex tasks.
- The module can be used as a drop-in replacement for the previous self-attention implementation in larger models.
This cell demonstrates a practical and extensible approach to implementing self-attention, making it suitable for advanced deep learning applications.
class SelfAttentionv2(nn.Module):
def __init__(self, input_dim, output_dim, qkv_bias = False):
super().__init__()
self.weight_query = nn.Linear(input_dim, output_dim, bias = qkv_bias)
self.weight_key = nn.Linear(input_dim, output_dim, bias = qkv_bias)
self.weight_value = nn.Linear(input_dim, output_dim, bias = qkv_bias)
def forward(self, x):
queries = self.weight_query(x)
keys = self.weight_key(x)
values = self.weight_value(x)
attention_scores = queries @ keys.T
scaling_factor = keys.shape[-1] ** 0.5
attention_weights = torch.softmax(attention_scores / scaling_factor, dim = -1)
context_vectors = attention_weights @ values
return context_vectors
Applying the Enhanced Self-Attention Module (SelfAttentionv2)¶
This cell demonstrates how to use the improved SelfAttentionv2 PyTorch module to compute context vectors for a batch of input embeddings. The enhancements include the use of nn.Linear layers for query, key, and value projections, and the option to include bias terms for greater flexibility.
Purpose of the Example
- Showcases the application of the enhanced self-attention module to a set of input embeddings.
- Illustrates how the module can be instantiated and used in a typical PyTorch workflow.
Calculation Steps
- The random seed is set for reproducibility of the linear layer initialization.
- An instance of
SelfAttentionv2is created with specified input and output dimensions. - The module is called with the input embeddings, producing context vectors for each input.
- The resulting context vectors are printed for inspection.
Code Explanation
self_attention_v2 = SelfAttentionv2(input_dim, output_dim)creates the enhanced attention layer.context_vectors_v2 = self_attention_v2(example_input_embeddings)applies the layer to the input data.- The output,
context_vectors_v2, contains the aggregated information for each input embedding, as determined by the attention mechanism.
Interpretation
- This example demonstrates the practical use of a more flexible self-attention layer, as found in advanced Transformer models.
- The context vectors can be used for further processing, such as classification, sequence modeling, or as input to additional network layers.
Advantages of the Enhanced Module
- Using
nn.Linearlayers allows for bias terms, which can improve model expressiveness. - The modular design makes it easy to integrate into larger architectures and experiment with different configurations.
- Using
This cell completes the demonstration of modular self-attention, showing how enhancements in layer design can lead to more powerful and adaptable deep learning models.
torch.manual_seed(123)
self_attention_v2 = SelfAttentionv2(input_dim, output_dim)
context_vectors_v2 = self_attention_v2(example_input_embeddings)
print(f"Context vectors from SelfAttentionv2 module:\n {context_vectors_v2}")
Context vectors from SelfAttentionv2 module:
tensor([[-0.5480, -0.1288],
[-0.5475, -0.1291],
[-0.5503, -0.1260],
[-0.5530, -0.1225],
[-0.5523, -0.1232],
[-0.5487, -0.1277]], grad_fn=<MmBackward0>)
Transferring Weights Between Self-Attention Modules and Comparing Outputs¶
This cell demonstrates how to transfer the learned weights from the enhanced SelfAttentionv2 module (which uses nn.Linear layers) to the original SelfAttention module (which uses raw nn.Parameter matrices), and then compares the outputs of both modules when applied to the same input embeddings.
Purpose of Weight Transfer
- Enables direct comparison between two different implementations of self-attention: one using
nn.Linearlayers and the other using raw parameter matrices. - Shows how to manually assign weights from one module to another, ensuring both modules use identical parameters for fair output comparison.
- Enables direct comparison between two different implementations of self-attention: one using
Calculation Steps
- The weights for query, key, and value projections are extracted from the
SelfAttentionv2module and transposed to match the shape expected by theSelfAttentionmodule. - These weights are assigned to the corresponding parameters in the
SelfAttentionmodule. - Both modules are then applied to the same input embeddings, and their context vector outputs are printed.
- The weights for query, key, and value projections are extracted from the
Code Explanation
self_attention.weight_key = nn.Parameter(self_attention_v2.weight_key.weight.T)assigns the transposed key weights.- Similar assignments are made for query and value weights.
- The context vectors are computed using the original
SelfAttentionmodule with the transferred weights. - The outputs from both modules can be compared to verify that, with identical weights, both implementations produce the same results (assuming no bias is used in
SelfAttentionv2).
Interpretation
- This process is useful for validating custom implementations against standard PyTorch layers.
- It demonstrates the flexibility of PyTorch modules and how weights can be shared or transferred between different architectures.
- Comparing outputs helps ensure correctness and consistency across different module designs.
Practical Implications
- Weight sharing and transfer are common in model experimentation, fine-tuning, and architecture comparisons.
- Understanding how to manipulate and assign weights is valuable for advanced model development and research.
This cell completes the demonstration by bridging two self-attention implementations, highlighting best practices for module comparison and weight management in PyTorch.
self_attention.weight_key = nn.Parameter(self_attention_v2.weight_key.weight.T)
self_attention.weight_query = nn.Parameter(self_attention_v2.weight_query.weight.T)
self_attention.weight_value = nn.Parameter(self_attention_v2.weight_value.weight.T)
context_vectors = self_attention(example_input_embeddings)
print(f"Context vectors from SelfAttention module:\n {context_vectors}")
Context vectors from SelfAttention module:
tensor([[-0.5480, -0.1288],
[-0.5475, -0.1291],
[-0.5503, -0.1260],
[-0.5530, -0.1225],
[-0.5523, -0.1232],
[-0.5487, -0.1277]], grad_fn=<MmBackward0>)
Causal Masking in Self-Attention: Implementation and Effects¶
This cell demonstrates how to apply causal masking to the attention weights in a self-attention mechanism, a technique commonly used in autoregressive models such as GPT and Transformer decoders. Causal masking ensures that each position in a sequence can only attend to itself and previous positions, preventing information “leakage” from future tokens.
Steps and Explanations¶
Compute Queries and Keys
- The input embeddings are projected into query and key spaces using the trained linear layers from the
SelfAttentionv2module. - These projections are used to calculate attention scores, which measure the similarity between each query and key.
- The input embeddings are projected into query and key spaces using the trained linear layers from the
Calculate Attention Weights
- Attention scores are scaled by the square root of the key dimension to stabilize gradients.
- The softmax function is applied to the scaled scores, producing attention weights that sum to 1 for each query.
Create the Causal Mask
- A lower-triangular matrix (
causal_mask) is generated usingtorch.tril, with ones on and below the diagonal and zeros above. - This mask ensures that each position can only attend to itself and previous positions in the sequence.
- A lower-triangular matrix (
Apply the Mask
- The attention weights are element-wise multiplied by the causal mask, zeroing out any weights that correspond to future positions.
Normalize Masked Attention Weights
- After masking, the attention weights for each query may no longer sum to 1.
- The masked weights are renormalized by dividing each row by its sum, ensuring they form a valid probability distribution.
Practical Importance¶
- Autoregressive Generation: Causal masking is essential for tasks like language modeling and text generation, where predictions for each token should not depend on future tokens.
- Preventing Information Leakage: By masking out future positions, the model maintains the correct temporal order and avoids using information it shouldn’t have access to.
- Generalization to Other Domains: Causal masking is also used in time series modeling and other sequential data tasks where causality must be preserved.
Output¶
- The cell prints the original attention weights, the causal mask, the masked attention weights, and the normalized masked attention weights.
- This allows you to observe how causal masking alters the attention distribution and enforces the autoregressive property.
This implementation provides a clear example of how causal masking is integrated into self-attention mechanisms, ensuring proper sequence modeling in deep learning architectures.
queries = self_attention_v2.weight_query(example_input_embeddings)
keys = self_attention_v2.weight_key(example_input_embeddings)
attention_scores = queries @ keys.T
scaling_factor = keys.shape[-1] ** 0.5
attention_weights = torch.softmax(attention_scores / scaling_factor, dim = -1)
print(f"All attention weights from SelfAttentionv2 module:\n {attention_weights}")
context_length = attention_weights.shape[0]
causal_mask = torch.tril(torch.ones(context_length, context_length))
print(f"Causal mask:\n {causal_mask}")
masked_attention_weights = attention_weights * causal_mask
print(f"Masked attention weights:\n {masked_attention_weights}")
normalized_masked_attention_weights = masked_attention_weights / (masked_attention_weights.sum(dim = -1, keepdim = True))
print(f"Normalized masked attention weights:\n {normalized_masked_attention_weights}")
All attention weights from SelfAttentionv2 module:
tensor([[0.1699, 0.1678, 0.1666, 0.1654, 0.1634, 0.1670],
[0.1701, 0.1690, 0.1659, 0.1642, 0.1633, 0.1675],
[0.1663, 0.1617, 0.1698, 0.1717, 0.1663, 0.1642],
[0.1616, 0.1544, 0.1735, 0.1797, 0.1701, 0.1607],
[0.1622, 0.1562, 0.1725, 0.1777, 0.1698, 0.1616],
[0.1684, 0.1659, 0.1675, 0.1674, 0.1647, 0.1661]],
grad_fn=<SoftmaxBackward0>)
Causal mask:
tensor([[1., 0., 0., 0., 0., 0.],
[1., 1., 0., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 1., 0., 0.],
[1., 1., 1., 1., 1., 0.],
[1., 1., 1., 1., 1., 1.]])
Masked attention weights:
tensor([[0.1699, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1701, 0.1690, 0.0000, 0.0000, 0.0000, 0.0000],
[0.1663, 0.1617, 0.1698, 0.0000, 0.0000, 0.0000],
[0.1616, 0.1544, 0.1735, 0.1797, 0.0000, 0.0000],
[0.1622, 0.1562, 0.1725, 0.1777, 0.1698, 0.0000],
[0.1684, 0.1659, 0.1675, 0.1674, 0.1647, 0.1661]],
grad_fn=<MulBackward0>)
Normalized masked attention weights:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5016, 0.4984, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3341, 0.3249, 0.3410, 0.0000, 0.0000, 0.0000],
[0.2415, 0.2307, 0.2593, 0.2685, 0.0000, 0.0000],
[0.1935, 0.1863, 0.2057, 0.2120, 0.2025, 0.0000],
[0.1684, 0.1659, 0.1675, 0.1674, 0.1647, 0.1661]],
grad_fn=<DivBackward0>)
Alternative Causal Masking with Upper-Triangular Mask and Softmax¶
This cell demonstrates an alternative approach to causal masking in self-attention mechanisms, using an upper-triangular mask and direct masking of attention scores before applying the softmax function. This method is commonly used in Transformer decoders and autoregressive models to prevent each position from attending to future tokens.
Steps and Explanations¶
Compute Queries and Keys
- The input embeddings are projected into query and key spaces using the trained linear layers from the
SelfAttentionv2module. - These projections are used to calculate attention scores, which measure the similarity between each query and key.
- The input embeddings are projected into query and key spaces using the trained linear layers from the
Calculate Raw Attention Scores
- The attention scores are computed as the dot product between queries and keys, resulting in a square matrix where each row corresponds to a query and each column to a key.
Create the Upper-Triangular Causal Mask
- An upper-triangular mask is generated using
torch.triu, with ones above the main diagonal and zeros on and below the diagonal. - This mask identifies positions in the attention score matrix that correspond to future tokens for each query.
- An upper-triangular mask is generated using
Apply the Mask to Attention Scores
- The attention scores corresponding to future positions are set to negative infinity (
-torch.inf) usingmasked_fill. - This ensures that, after applying softmax, the attention weights for future positions become zero.
- The attention scores corresponding to future positions are set to negative infinity (
Scale and Normalize Masked Attention Scores
- The masked attention scores are scaled by the square root of the key dimension to stabilize gradients.
- The softmax function is applied to the scaled, masked scores, producing attention weights that sum to 1 for each query and only allow attention to current and previous positions.
Practical Importance¶
- Autoregressive Modeling: This masking technique is essential for tasks like language modeling and sequence generation, where each token should only attend to itself and previous tokens.
- Efficient Implementation: Masking attention scores before softmax is computationally efficient and ensures strict causality in the attention mechanism.
- Generalization: This approach is widely used in Transformer decoders and other models that require autoregressive behavior.
Output¶
- The cell prints the masked attention scores and the resulting masked attention weights after softmax.
- This allows you to observe how the upper-triangular mask enforces causality and alters the attention distribution.
This implementation provides a robust and efficient method for causal masking in self-attention, ensuring proper sequence modeling and preventing information leakage from future tokens.
queries = self_attention_v2.weight_query(example_input_embeddings)
keys = self_attention_v2.weight_key(example_input_embeddings)
attention_scores = queries @ keys.T
context_length = attention_scores.shape[0]
causal_mask = torch.triu(torch.ones(context_length, context_length), diagonal = 1)
masked_attention_scores = attention_scores.masked_fill(causal_mask.bool(), -torch.inf)
print(f"Masked attention scores:\n {masked_attention_scores}")
scaling_factor = keys.shape[-1] ** 0.5
masked_attention_weights = torch.softmax(masked_attention_scores / scaling_factor, dim = -1)
print(f"Masked attention weights:\n {masked_attention_weights}")
Masked attention scores:
tensor([[0.1152, -inf, -inf, -inf, -inf, -inf],
[0.0792, 0.0699, -inf, -inf, -inf, -inf],
[0.1842, 0.1447, 0.2133, -inf, -inf, -inf],
[0.2565, 0.1920, 0.3571, 0.4066, -inf, -inf],
[0.2107, 0.1570, 0.2971, 0.3396, 0.2750, -inf],
[0.1188, 0.0975, 0.1117, 0.1106, 0.0875, 0.0997]],
grad_fn=<MaskedFillBackward0>)
Masked attention weights:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5016, 0.4984, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3341, 0.3249, 0.3410, 0.0000, 0.0000, 0.0000],
[0.2415, 0.2307, 0.2593, 0.2685, 0.0000, 0.0000],
[0.1935, 0.1863, 0.2057, 0.2120, 0.2025, 0.0000],
[0.1684, 0.1659, 0.1675, 0.1674, 0.1647, 0.1661]],
grad_fn=<SoftmaxBackward0>)
Dropout in Attention Mechanisms: Regularizing Masked Attention Weights¶
This cell demonstrates how to apply dropout to masked attention weights in a self-attention mechanism. Dropout is a regularization technique that helps prevent overfitting by randomly zeroing out elements of a tensor during training. In the context of attention mechanisms, dropout is commonly applied to the attention weights to improve generalization and model robustness.
Steps and Explanations¶
Set the Random Seed
- The random seed is set for reproducibility, ensuring that the dropout pattern is consistent across runs.
Instantiate the Dropout Layer
- A PyTorch
nn.Dropoutlayer is created with a dropout probability of 0.5, meaning half of the attention weights will be randomly set to zero during training.
- A PyTorch
Apply Dropout to Masked Attention Weights
- The dropout layer is applied to the previously computed masked attention weights, producing
masked_dropped_attention_weights. - This operation randomly zeroes out elements in the attention weights matrix, simulating the effect of ignoring certain attention connections during training.
- The dropout layer is applied to the previously computed masked attention weights, producing
Print the Result
- The resulting attention weights after dropout are printed, allowing you to observe the effect of regularization on the attention distribution.
Practical Importance¶
- Preventing Overfitting: Dropout helps the model avoid relying too heavily on specific attention connections, encouraging it to learn more robust and distributed representations.
- Improving Generalization: By randomly dropping attention weights, the model is forced to consider alternative paths and relationships in the data, which can improve performance on unseen examples.
- Standard Practice: Dropout is widely used in Transformer architectures and other attention-based models, typically applied to the attention weights or the output of the attention layer.
Output¶
- The cell prints the masked attention weights after dropout, showing which connections have been zeroed out.
- This visualization helps illustrate how dropout acts as a regularizer in attention mechanisms.
This cell completes the demonstration of regularization in self-attention, highlighting the role of dropout in building robust and generalizable deep learning models.
torch.manual_seed(123)
dropout = nn.Dropout(0.5)
masked_dropped_attention_weights = dropout(masked_attention_weights)
print(f"Masked attention weights with dropout:\n {masked_dropped_attention_weights}")
Masked attention weights with dropout:
tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.6682, 0.6498, 0.6821, 0.0000, 0.0000, 0.0000],
[0.0000, 0.4614, 0.5186, 0.0000, 0.0000, 0.0000],
[0.0000, 0.3726, 0.0000, 0.4239, 0.0000, 0.0000],
[0.0000, 0.3317, 0.3351, 0.3348, 0.3294, 0.0000]],
grad_fn=<MulBackward0>)
Causal Masking in Batched Self-Attention Modules: Detailed Explanation¶
This cell defines a custom PyTorch module, CausalAttention, which implements self-attention with causal masking and dropout for batched input sequences. This approach is essential for autoregressive models, such as GPT and Transformer decoders, where each token should only attend to itself and previous tokens, not future ones.
Key Steps and Concepts¶
Module Initialization
- The module takes
input_dim,output_dim,dropout,context_length, and an optionalqkv_biasas arguments. - Three linear layers are created for projecting input embeddings into queries, keys, and values.
- A dropout layer is initialized for regularization.
- The causal mask is registered as a buffer, using an upper-triangular matrix to identify future positions.
- The module takes
Forward Pass
- The input tensor
xis expected to have shape[batch_size, num_tokens, input_dim]. - Queries, keys, and values are computed for each token in the batch using the respective linear layers.
- Attention scores are calculated as the dot product between queries and keys, resulting in a
[batch_size, num_tokens, num_tokens]matrix.
- The input tensor
Causal Masking
- The causal mask is sliced to match the current sequence length (
num_tokens). attention_scores.masked_fill_(self.causal_mask.bool()[:num_tokens, :num_tokens], -torch.inf)sets attention scores for future positions to negative infinity.- This ensures that, after softmax, each token can only attend to itself and previous tokens.
- The causal mask is sliced to match the current sequence length (
Scaling and Softmax
- Attention scores are scaled by the square root of the key dimension to stabilize gradients.
- Softmax is applied along the last dimension, converting scores into attention weights that sum to 1 for each query.
Dropout Regularization
- Dropout is applied to the attention weights, randomly zeroing out some connections during training to prevent overfitting.
Context Vector Computation
- The final context vectors are computed as a weighted sum of the value vectors, using the masked and regularized attention weights.
- The output is a tensor of shape
[batch_size, num_tokens, output_dim], suitable for further processing in sequence models.
Practical Importance¶
- Autoregressive Modeling: Causal masking is critical for tasks like language modeling and sequence generation, ensuring predictions for each token do not depend on future tokens.
- Efficient Batch Processing: The module supports batched inputs, making it suitable for training and inference on large datasets.
- Regularization: Dropout improves generalization by preventing the model from relying too heavily on specific attention connections.
Output¶
- The module returns context vectors for each token in the batch, with causality and regularization enforced.
- This implementation is a robust building block for modern Transformer-based architectures.
This cell demonstrates how to combine causal masking and dropout in a modular, batched self-attention layer, providing both theoretical rigor and practical utility for deep learning models.
class CausalAttention(nn.Module):
def __init__(self, input_dim, output_dim, dropout, context_length, qkv_bias = False):
super().__init__()
self.query_weight = nn.Linear(input_dim, output_dim, qkv_bias)
self.key_weight = nn.Linear(input_dim, output_dim, qkv_bias)
self.value_weight = nn.Linear(input_dim, output_dim, qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer("causal_mask", torch.triu(torch.ones(context_length, context_length), diagonal = 1))
def forward(self, x):
num_tokens = x.shape[1]
queries = self.query_weight(x)
keys = self.key_weight(x)
values = self.value_weight(x)
attention_scores = queries @ keys.transpose(1,2)
attention_scores.masked_fill_(self.causal_mask.bool()[:num_tokens, :num_tokens], -torch.inf)
scaling_factor = keys.shape[-1] ** 0.5
attention_weights = torch.softmax(attention_scores / scaling_factor, dim = -1)
attention_weights = self.dropout(attention_weights)
context_vectors = attention_weights @ values
return context_vectors
Running the CausalAttention Module: Batched Context Vector Computation¶
This cell demonstrates how to use the custom CausalAttention module to compute context vectors for a batch of input sequences, with causal masking and dropout applied. It shows the practical application of the module in a typical deep learning workflow.
Steps and Explanations¶
Batch Creation
- Two copies of the example input embeddings are stacked to form a batch, resulting in a tensor of shape
[batch_size, num_tokens, input_dim]. - This simulates processing multiple sequences in parallel, as is common during training and inference.
- Two copies of the example input embeddings are stacked to form a batch, resulting in a tensor of shape
Context Length and Dropout
- The context length is set to the number of tokens in each sequence.
- Dropout probability is specified (e.g., 0.2) to regularize the attention weights.
Module Instantiation
- The
CausalAttentionmodule is instantiated with the input dimension, output dimension, dropout rate, and context length. - This sets up the module with causal masking and dropout for batched inputs.
- The
Forward Pass
- The batched input embeddings are passed through the
CausalAttentionmodule. - The module computes queries, keys, and values, applies causal masking to the attention scores, scales and normalizes them, applies dropout, and computes the context vectors for each token in each sequence.
- The batched input embeddings are passed through the
Output
- The resulting context vectors have shape
[batch_size, num_tokens, output_dim], representing the aggregated information for each token in each sequence, with causality and regularization enforced. - The output is printed for inspection.
- The resulting context vectors have shape
Practical Importance¶
- Batch Processing: Efficiently processes multiple sequences in parallel, which is essential for scalable training and inference.
- Causal Masking: Ensures each token only attends to itself and previous tokens, preserving autoregressive properties.
- Dropout Regularization: Improves generalization by randomly dropping attention connections during training.
Summary¶
This cell provides a complete example of how to use a modular, batched self-attention layer with causal masking and dropout in PyTorch. It highlights best practices for sequence modeling and demonstrates how to integrate advanced attention mechanisms into deep learning pipelines.
torch.manual_seed(123)
batched_input_embeddings = torch.stack([example_input_embeddings, example_input_embeddings], dim = 0)
context_length = batched_input_embeddings.shape[1]
dropout = 0.2
causal_attention = CausalAttention(input_dim, output_dim, dropout, context_length)
context_vectors_causal = causal_attention(batched_input_embeddings)
print(f"Context vectors from CausalAttention module:\n {context_vectors_causal}")
Context vectors from CausalAttention module:
tensor([[[-0.6411, -0.2989],
[-0.5690, -0.2869],
[-0.6798, -0.3041],
[-0.7194, -0.1945],
[-0.7039, -0.1326],
[-0.4672, -0.1319]],
[[ 0.0000, 0.0000],
[-0.5690, -0.2869],
[-0.5185, -0.2148],
[-0.7194, -0.1945],
[-0.7039, -0.1326],
[-0.5828, -0.1157]]], grad_fn=<UnsafeViewBackward0>)
Multi-Head Causal Attention: Concept and Implementation¶
This cell introduces the SimpleMultiHeadAttention module, which extends the causal self-attention mechanism to support multiple attention heads. Multi-head attention is a core component of Transformer architectures, enabling the model to capture diverse relationships and patterns in the input sequence.
Key Concepts¶
Multi-Head Attention
- Instead of a single attention mechanism, multiple independent attention heads are used.
- Each head learns to focus on different aspects or relationships within the input sequence.
- The outputs of all heads are concatenated to form a richer, more expressive representation.
Module Structure
- The module takes
input_dim,output_dim,dropout,context_length,num_heads, and an optionalqkv_biasas arguments. - A list of
CausalAttentionmodules is created, one for each head, usingnn.ModuleList. - Each head operates independently on the same input.
- The module takes
Forward Pass
- The input tensor
xis passed through each attention head, producing a list of context vector outputs. - The outputs from all heads are concatenated along the last dimension, resulting in a tensor of shape
[batch_size, num_tokens, num_heads * output_dim]. - This concatenated output can be further processed by subsequent layers in the model.
- The input tensor
Practical Importance¶
- Diversity of Attention: Multi-head attention allows the model to attend to information from different representation subspaces, improving its ability to capture complex dependencies.
- Expressiveness: Concatenating multiple attention outputs provides a richer feature set for downstream tasks.
- Scalability: The modular design makes it easy to adjust the number of heads and output dimensions for different model sizes and applications.
Summary¶
This cell demonstrates how to implement multi-head causal attention by combining several independent attention modules. It highlights the advantages of multi-head architectures in deep learning and provides a foundation for building advanced Transformer models.
class SimpleMultiHeadAttention(nn.Module):
def __init__(self, input_dim, output_dim, dropout, context_length, num_heads, qkv_bias = False):
super().__init__()
self.heads = nn.ModuleList(
[CausalAttention(input_dim, output_dim, dropout, context_length, qkv_bias)
for _ in range(num_heads)]
)
def forward(self, x):
head_outputs = [head(x) for head in self.heads]
concat_output = torch.cat(head_outputs, dim = -1)
return concat_output
Using Multi-Head Causal Attention: Parallel Sequence Representation¶
This cell demonstrates how to instantiate and apply the SimpleMultiHeadAttention module to a batch of input sequences. It shows how multi-head causal attention can be used to generate rich, parallel representations for each token in a sequence.
Steps and Explanations¶
Batch Preparation
- The input embeddings are stacked to create a batch, simulating multiple sequences processed in parallel.
- This is typical in training and inference for deep learning models.
Module Instantiation
- The
SimpleMultiHeadAttentionmodule is created with specified input and output dimensions, dropout rate, context length, and number of heads. - Each head is an independent causal attention module, allowing the model to learn diverse attention patterns.
- The
Forward Pass
- The batched input embeddings are passed through the multi-head attention module.
- Each head computes its own context vectors, and the outputs are concatenated along the last dimension.
- The result is a tensor of shape
[batch_size, num_tokens, num_heads * output_dim], providing a rich representation for each token.
Output
- The context vectors from all heads are printed, showing how multi-head attention aggregates information from different perspectives.
Practical Importance¶
- Parallel Attention: Multiple heads allow the model to focus on different relationships and features in the sequence simultaneously.
- Expressive Representations: Concatenating outputs from several heads yields a more informative feature set for downstream tasks.
- Scalability: The approach is efficient and scalable, suitable for large models and datasets.
Summary¶
This cell provides a practical example of using multi-head causal attention to process batched input sequences. It highlights the benefits of parallel attention mechanisms and demonstrates how to integrate them into modern deep learning workflows.
torch.manual_seed(123)
num_heads = 3
simple_multi_head_attention = SimpleMultiHeadAttention(input_dim, output_dim, dropout, context_length, num_heads)
context_vectors_simple_multi_head = simple_multi_head_attention(batched_input_embeddings)
print(f"Context vectors from SimpleMultiHeadAttention module:\n {context_vectors_simple_multi_head}")
print(f"Shape: {context_vectors_simple_multi_head.shape}")
Context vectors from SimpleMultiHeadAttention module:
tensor([[[-0.6411, -0.2989, 0.5830, 0.5474, 0.6471, 0.3096],
[-0.5690, -0.2869, 0.2212, 0.2294, 0.3217, 0.1539],
[-0.5185, -0.2148, 0.6319, 0.5352, 0.6957, 0.2858],
[-0.3459, -0.1508, 0.6740, 0.4963, 0.4929, 0.2423],
[-0.4001, -0.1784, 0.4313, 0.2915, 0.6202, 0.2783],
[-0.3938, -0.0890, 0.5032, 0.3488, 0.5450, 0.2628]],
[[-0.6411, -0.2989, 0.5830, 0.5474, 0.6471, 0.3096],
[-0.5690, -0.2869, 0.2212, 0.2294, 0.3217, 0.1539],
[-0.6798, -0.3041, 0.6319, 0.5352, 0.6957, 0.2858],
[-0.7194, -0.1945, 0.6740, 0.4963, 0.5811, 0.2489],
[-0.7039, -0.1326, 0.3620, 0.2731, 0.4472, 0.1912],
[-0.4969, -0.1330, 0.6556, 0.4547, 0.6202, 0.2750]]],
grad_fn=<CatBackward0>)
Shape: torch.Size([2, 6, 6])
Multi-Head Attention Module: Efficient and Flexible Transformer Attention¶
This cell defines a robust and efficient MultiHeadAttention PyTorch module, implementing the multi-head causal self-attention mechanism as used in Transformer architectures. The module supports batching, dropout, causal masking, and output projection, making it suitable for advanced sequence modeling tasks.
Key Features and Steps¶
Multi-Head Attention Structure
- The input is projected into queries, keys, and values using separate linear layers.
- The projections are reshaped and transposed to create multiple attention heads, allowing the model to learn diverse relationships in parallel.
- Each head operates independently on a subspace of the input features.
Causal Masking
- A causal mask is applied to the attention scores to prevent each token from attending to future tokens, enforcing autoregressive behavior.
- This is essential for tasks like language modeling and sequence generation.
Attention Score Calculation
- Attention scores are computed as the dot product between queries and keys for each head.
- Scores are scaled by the square root of the head dimension to stabilize gradients.
Softmax and Dropout
- Softmax is applied to the scaled attention scores to obtain attention weights, which sum to 1 for each query.
- Dropout is applied to the attention weights for regularization, helping prevent overfitting.
Context Vector Computation
- The attention weights are used to compute weighted sums of the value vectors for each head.
- The outputs from all heads are concatenated and projected back to the original output dimension using a final linear layer.
Output
- The module returns context vectors for each token in the batch, with shape
[batch_size, num_tokens, output_dim]. - These vectors aggregate information from the entire sequence, with causality and regularization enforced.
- The module returns context vectors for each token in the batch, with shape
Practical Importance¶
- Expressiveness: Multi-head attention enables the model to capture complex dependencies and relationships in the input sequence.
- Scalability: The module efficiently processes batched inputs and supports flexible configuration of head and output dimensions.
- Autoregressive Modeling: Causal masking ensures proper sequence modeling for tasks like text generation and time series prediction.
- Regularization: Dropout improves generalization by randomly dropping attention connections during training.
Summary¶
This implementation provides a comprehensive and modular approach to multi-head causal self-attention, suitable for integration into modern Transformer-based models. It demonstrates best practices for efficient, flexible, and regularized attention mechanisms in deep learning.
class MultiHeadAttention(nn.Module):
def __init__(self, input_dim, output_dim, dropout, context_length, num_heads, qkv_bias = False):
super().__init__()
assert output_dim % num_heads == 0, "Output dimension must be divisible by number of heads"
self.output_dim = output_dim
self.num_heads = num_heads
self.head_dim = output_dim // num_heads
self.weight_query = nn.Linear(input_dim, output_dim, qkv_bias)
self.weight_key = nn.Linear(input_dim, output_dim, qkv_bias)
self.weight_value = nn.Linear(input_dim, output_dim, qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer("causal_mask", torch.triu(torch.ones(context_length, context_length), diagonal = 1))
self.output_projection = nn.Linear(output_dim, output_dim)
def forward(self, x):
batch_size, num_tokens, _ = x.shape
queries = self.weight_query(x).view(batch_size, num_tokens, self.num_heads, self.head_dim).transpose(1,2)
keys = self.weight_key(x).view(batch_size, num_tokens, self.num_heads, self.head_dim).transpose(1,2)
values = self.weight_value(x).view(batch_size, num_tokens, self.num_heads, self.head_dim).transpose(1,2)
attention_scores = queries @ keys.transpose(2,3)
attention_scores.masked_fill_(self.causal_mask.bool()[:num_tokens, :num_tokens], -torch.inf)
attention_weights = torch.softmax(attention_scores / keys.shape[-1]**0.5, dim = -1)
attention_weights = self.dropout(attention_weights)
context_vectors = self.output_projection((attention_weights @ values).transpose(1,2).contiguous().view(batch_size, num_tokens, self.output_dim))
return context_vectors
Multi-Head Attention: Batched Context Vector Computation and Output Analysis¶
This cell demonstrates how to use the MultiHeadAttention module to compute context vectors for a batch of input sequences using multi-head causal self-attention. Multi-head attention is a key component of Transformer architectures, allowing the model to capture diverse relationships in the input data by attending to different representation subspaces in parallel.
Steps and Explanations¶
Random Seed Initialization
- The random seed is set for reproducibility, ensuring that the initialization of weights and dropout patterns is consistent across runs.
Parameter Setup
input_dim: The dimensionality of each input embedding (here, 3).output_dim: The total output dimension after concatenating all attention heads (here, 6).dropout: The dropout probability (here, 0.2), used to regularize the attention weights.context_length: The number of tokens in each input sequence (here, 6).num_heads: The number of parallel attention heads (here, 3).
Module Instantiation
- The
MultiHeadAttentionmodule is instantiated with the specified parameters. - Internally, the module creates separate linear layers for query, key, and value projections, splits the output dimension across multiple heads, applies causal masking to enforce autoregressive behavior, and includes a final output projection layer.
- The
Forward Pass
- The batched input embeddings (
batched_input_embeddings) are passed through the multi-head attention module. - For each sequence in the batch, the module computes queries, keys, and values for each head, applies causal masking to prevent attention to future tokens, calculates scaled dot-product attention scores, normalizes them with softmax, applies dropout, and computes context vectors by aggregating the value vectors.
- The outputs from all heads are concatenated and projected to the final output dimension.
- The batched input embeddings (
Output
- The resulting
context_vectorstensor has shape[batch_size, context_length, output_dim], representing the aggregated information for each token in each sequence, with contributions from all attention heads. - The output is printed for inspection, allowing you to analyze how multi-head attention distributes focus across the input sequence.
- The resulting
Practical Importance¶
- Expressive Representations: Multi-head attention enables the model to learn and represent complex dependencies in the input data by attending to different aspects in parallel.
- Autoregressive Modeling: Causal masking ensures that each token only attends to itself and previous tokens, which is essential for tasks like language modeling and sequence generation.
- Regularization: Dropout helps prevent overfitting by randomly dropping attention connections during training.
- Scalability: The module efficiently processes batched inputs and supports flexible configuration of head and output dimensions.
Summary¶
This cell provides a complete example of applying multi-head causal attention to batched input sequences, highlighting the advantages of parallel attention mechanisms and demonstrating how to integrate them into modern deep learning workflows.
torch.manual_seed(123)
input_dim = batched_input_embeddings.shape[-1]
output_dim = 6
dropout = 0.2
context_length = batched_input_embeddings.shape[1]
num_heads = 3
multi_head_attention = MultiHeadAttention(input_dim, output_dim, dropout, context_length, num_heads)
context_vectors = multi_head_attention(batched_input_embeddings)
print(f"Context vectors from MultiHeadAttention module:\n {context_vectors}")
Context vectors from MultiHeadAttention module:
tensor([[[-0.5541, 0.0125, 0.2086, 0.3608, -0.0163, 0.1243],
[-0.5025, 0.0758, 0.0628, 0.3633, -0.0425, 0.0346],
[-0.4246, 0.0624, 0.3454, 0.4126, -0.0856, 0.2563],
[-0.2565, 0.0844, 0.2199, 0.6000, -0.1633, 0.2833],
[-0.3168, -0.0127, 0.4560, 0.5945, -0.1321, 0.4386],
[-0.3281, 0.0271, 0.2888, 0.5457, -0.1322, 0.3014]],
[[-0.4187, -0.1174, 0.2735, 0.6119, -0.0837, 0.2908],
[-0.4279, 0.0210, 0.0660, 0.4885, -0.0798, 0.0995],
[-0.4039, -0.0576, 0.3259, 0.5950, -0.0789, 0.3235],
[-0.3660, -0.0625, 0.3912, 0.6157, -0.0995, 0.3895],
[-0.3168, -0.0127, 0.4560, 0.5945, -0.1321, 0.4386],
[-0.3541, 0.0049, 0.4174, 0.5522, -0.1166, 0.3840]]],
grad_fn=<ViewBackward0>)
Leave a Reply