
In Part 1 of this series, I built a simple neural network for classification to get comfortable with the basics of deep learning. In Part 2, I created a MiniTokenizer to understand how raw text is transformed into tokens. Now, in Part 3, I am moving one step closer to building a GPT-style model by focusing on data preparation.
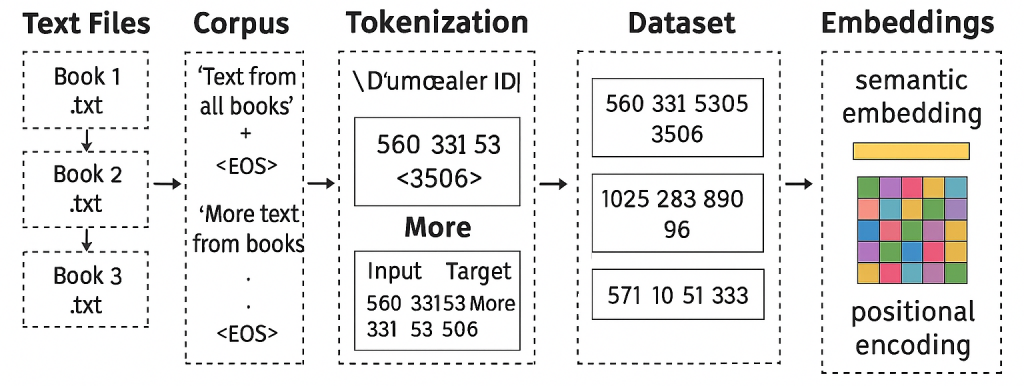
Training a large language model (LLM) is not just about designing the architecture. The quality and structure of the data pipeline determine how well the model can learn. This phase is where raw text is cleaned, tokenized, and organized into batches that a transformer can process efficiently. Without a solid data preparation workflow, even the best model design will fail to deliver.
Why Data Preparation Matters
Language models learn by predicting the next token in a sequence. To do this effectively, the training data must be:
- Unified: scattered text files need to be combined into a single corpus
- Tokenized: text must be converted into numerical IDs
- Structured: sequences must be sliced into manageable chunks
- Batched: data must be grouped for efficient GPU training
This process ensures that the model sees consistent, well-structured input and can learn patterns across a large body of text.
Building the Corpus
For this experiment, I created a test corpus of 20 books from Project Gutenberg. These books span philosophy, science, and literature, giving the model a diverse set of writing styles and vocabularies. Each book is stored as a .txt file in a books/ directory.
The first step is to merge them into a single file. I added a special token between documents to mark boundaries. This helps the model understand where one context ends and another begins.
from pathlib import Path
files = Path('./books').glob('*.txt')
with open('all_books.txt', 'w', encoding='utf-8') as outfile:
for file in files:
text = Path(file).read_text(encoding='utf-8')
outfile.write(text + '<EOS>')The result is a large text file containing all 20 books, ready for tokenization.
Tokenization with tiktoken
In Part 2, I built a MiniTokenizer to understand the basics. For this step, I switched to OpenAI’s tiktoken, which is optimized for speed and memory efficiency. It is the same tokenizer used in GPT models and supports subword tokenization through Byte Pair Encoding (BPE).
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
with open("all_books.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
token_ids = enc.encode(raw_text)
print(f"Total tokens: {len(token_ids)}")This converts the entire corpus into a sequence of integers. Each integer corresponds to a subword unit, which allows the model to handle rare words and character-level variations more effectively than word-level tokenization.
Creating a PyTorch Dataset
Once tokenized, the data must be structured into sequences for training. I defined a custom PyTorch Dataset that slices the tokenized corpus into overlapping windows. Each input sequence is paired with a target sequence shifted by one token, so the model learns to predict the next token.
import torch
from torch.utils.data import Dataset
class BooksDataset(Dataset):
def __init__(self, token_ids, max_length=128, step_size=64):
self.token_ids = token_ids
self.max_length = max_length
self.step_size = step_size
def __len__(self):
return (len(self.token_ids) - self.max_length) // self.step_size
def __getitem__(self, idx):
start = idx * self.step_size
end = start + self.max_length
x = torch.tensor(self.token_ids[start:end], dtype=torch.long)
y = torch.tensor(self.token_ids[start+1:end+1], dtype=torch.long)
return x, yThis design allows flexibility. By adjusting max_length and step_size, you can control how much context the model sees and how much overlap exists between sequences.
Batching with DataLoader
To train efficiently on GPUs, data must be batched. PyTorch’s DataLoader handles batching and shuffling. I also added a custom collate function to ensure sequences are padded correctly when needed.
from torch.utils.data import DataLoader
dataset = BooksDataset(token_ids, max_length=128, step_size=64)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in dataloader:
x, y = batch
print(x.shape, y.shape)
breakThis produces batches of shape (batch_size, sequence_length), which is exactly what a transformer expects.
Adding Embeddings
Transformers cannot work directly with token IDs. They need embeddings that map each token ID to a dense vector. I also included positional embeddings so the model can understand the order of tokens.
import torch.nn as nn
vocab_size = enc.n_vocab
embed_dim = 256
max_length = 128
token_embedding = nn.Embedding(vocab_size, embed_dim)
pos_embedding = nn.Embedding(max_length, embed_dim)These embeddings will be combined in the transformer model to provide both semantic and positional context.
Lessons Learned
- Corpus design matters: Choosing diverse texts helps the model generalize better.
- Special tokens are essential: markers give the model clear boundaries.
- Tokenization is powerful: Subword tokenization handles rare words more gracefully than word-level approaches.
- Batching is critical: Efficient batching ensures training runs smoothly on GPUs.
- Inspect everything: Checking token counts, sequence shapes, and batch outputs before training prevents costly mistakes later.
Try It Yourself
You can run this workflow with your own text data. The repository is available on GitHub:
👉 Data Preparation Repository
Clone the repo, add your .txt files to the books/ directory, and run the notebook. You can experiment with different sequence lengths, batch sizes, and tokenizers.
Build It Yourself
If you want to try building it yourself, you can find the complete code with detailed explanations of each block in the source code section at the end of this post. All the best!
What’s Next
With the data pipeline in place, I am ready to move on to the transformer architecture itself. In Part 4, I will implement the building blocks of GPT: attention mechanisms, transformer layers, and causal masking. This is where the model starts to come alive.
Stay tuned for Part 4.
Source Code
import tiktoken
from importlib.metadata import version
import torch
from torch.utils.data import Dataset, DataLoader
from pathlib import Path
Tokenization with tiktoken¶
This cell demonstrates how to use the tiktoken library for tokenizing and detokenizing text, which is essential for working with language models such as those from OpenAI.
Steps Covered¶
- Install and Import tiktoken: Ensure the
tiktokenlibrary is installed and import it along with theversionutility. - Check tiktoken Version: Print the installed version of
tiktokento verify the setup. - Initialize Tokenizer: Load the
cl100k_baseencoding, which is commonly used for OpenAI models. - Explore Vocabulary Size: Display the size of the tokenizer’s vocabulary.
- Tokenize Sample Text: Encode a sample string into tokens and display the result.
- Decode Tokens: Convert the tokens back to text and verify the output.
Note: Tokenization is the process of converting text into a sequence of tokens (numbers) that a model can understand. Detokenization is the reverse process, converting tokens back into human-readable text.
print(f'Tiktoken version: {version('tiktoken')}')
tokenizer = tiktoken.get_encoding("cl100k_base")
print(f'Vocabulary size: {tokenizer.n_vocab}')
sample_text = "Hello, world! This is a test of how well the tokenizer works."
tokens = tokenizer.encode(sample_text)
print(f'Encoded tokens: {tokens}')
decoded = tokenizer.decode(tokens)
print(f'Decoded text: {decoded}')
Tiktoken version: 0.11.0 Vocabulary size: 100277 Encoded tokens: [9906, 11, 1917, 0, 1115, 374, 264, 1296, 315, 1268, 1664, 279, 47058, 4375, 13] Decoded text: Hello, world! This is a test of how well the tokenizer works.
Combine Text Files for LLM Training¶
This cell merges all .txt files from the books directory into a single file, all_books.txt, with each book separated by an <EOS> (End Of Sequence) token. This is a common preprocessing step for language model training, allowing the model to learn document boundaries.
What the Code Does¶
- Finds all
.txtfiles in thebooksdirectory usingPath.glob. - Opens
all_books.txtfor writing in UTF-8 encoding. - Iterates through each file, reads its content, and writes it to the output file.
- Appends
<EOS>after each book to mark the end of a document.
Why use
<EOS>?The
<EOS>token helps the language model distinguish where one document ends and another begins. This is important for tasks like text generation, where you want the model to respect document boundaries.
files = Path('./books').glob('*.txt')
with open('all_books.txt', 'w', encoding='utf-8') as outfile:
for file in files:
outfile.write(Path(file).read_text(encoding='utf-8') + '<EOS>')
Tokenize the Combined Text Corpus¶
This cell reads the entire combined text file (all_books.txt) and tokenizes it using the tiktoken tokenizer. Tokenization is a crucial preprocessing step for training language models, as it converts raw text into a sequence of tokens (integers) that the model can understand.
What the Code Does¶
- Reads the full corpus: Loads all text from
all_books.txtinto memory. - Tokenizes the text: Uses the
tokenizer.encode()method to convert the text into a list of tokens. - Prints the token count: Displays the total number of tokens, which is useful for estimating dataset size and batching during training.
Tip: Knowing the total number of tokens helps you plan batch sizes, training steps, and memory requirements for your LLM training pipeline.
with(open('all_books.txt', 'r', encoding = 'utf-8') as textfile):
all_text = textfile.read()
encoded_text = tokenizer.encode(all_text)
print(f'Total number of tokens: {len(encoded_text)}')
Total number of tokens: 4962540
Creating a PyTorch Dataset for Language Model Training¶
This cell defines a custom BooksDataset class, which prepares tokenized text data for training an autoregressive language model (such as GPT). The dataset generates input and target sequences for each training example, enabling the model to learn to predict the next token in a sequence.
What the Code Does¶
- Initializes the Dataset: Takes the full text, a tokenizer, a maximum sequence length (
max_length), and a step size (step size between sequences). - Tokenizes the Text: Encodes the entire text into tokens using the provided tokenizer.
- Creates Overlapping Chunks: For each position in the tokenized text, creates an input chunk of length
max_lengthand a target chunk that is shifted by one token (the next-token prediction target). - Stores as Tensors: Converts each chunk into a PyTorch tensor for efficient batching and training.
- Implements
__len__and__getitem__: Standard PyTorch Dataset methods for compatibility with DataLoader.
Tip:
- Adjust
max_lengthandstrideto control the size and overlap of training samples.- This dataset structure is ideal for next-token prediction tasks, where the model learns to generate text one token at a time.
class BooksDataset(Dataset):
def __init__(self, text, tokenizer, max_length, step_size):
self.input_ids = []
self.target_ids = []
encoded_text = tokenizer.encode(text)
for i in range(0, len(encoded_text) - max_length, step_size):
input_chunk = encoded_text[i:i + max_length]
target_chunk = encoded_text[i + 1 : i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, index):
return self.input_ids[index], self.target_ids[index]
Utility Function: Create DataLoader for LLM Training¶
This cell defines a helper function, create_dataloader, which streamlines the process of preparing a PyTorch DataLoader for language model training. It takes raw text and returns a DataLoader that yields batches of input and target token sequences, ready for model training.
What the Code Does¶
- Defines
create_dataloader: Accepts the full text, maximum sequence length, step size (stride), and batch size as arguments. - Initializes the Tokenizer: Uses the
cl100k_baseencoding fromtiktokenfor tokenization. - Creates a
BooksDataset: Uses the custom dataset class to generate input-target pairs from the tokenized text. - Builds a DataLoader: Wraps the dataset in a PyTorch DataLoader for efficient batching, shuffling, and parallel data loading.
- Returns the DataLoader: Ready to be used in a training loop for next-token prediction tasks.
Tip:
- Adjust
max_length,step_size, andbatch_sizeto fit your model and hardware constraints.- This function abstracts away the repetitive setup code, making your training pipeline cleaner and more modular.
def create_dataloader(text, max_length = 512, step_size = 256, batch_size = 8, shuffle = True):
tokenizer = tiktoken.get_encoding('cl100k_base')
dataset = BooksDataset(text,tokenizer, max_length, step_size)
dataloader = DataLoader(
dataset = dataset,
batch_size = batch_size,
shuffle = shuffle,
drop_last = True,
num_workers = 0
)
return dataloader
Example: Using the DataLoader for Batching¶
This cell demonstrates how to use the create_dataloader utility to generate batches of input and target sequences for language model training. It shows how to iterate through the DataLoader and inspect the structure of each batch.
What the Code Does¶
- Creates a DataLoader: Calls
create_dataloaderwith the full text, a batch size of 2, a maximum sequence length of 8, and a step size of 4. Shuffling is disabled for demonstration purposes. - Iterates Through Batches: Loops through the DataLoader and prints the first 4 batches, showing the input and target tensors for each batch.
- Batch Structure: Each batch contains a tuple of input and target tensors, where:
- The input tensor is a sequence of token IDs of length
max_length. - The target tensor is the same sequence shifted by one token (for next-token prediction).
- The input tensor is a sequence of token IDs of length
Tip:
- Adjust
batch_size,max_length, andstep_sizeto match your model and hardware.- Inspecting batches before training helps verify that your data pipeline is working as expected.
dataloader = create_dataloader(all_text, batch_size = 2, max_length = 8, step_size = 4, shuffle = False)
for i, batch in enumerate(dataloader):
print(f"Batch {i}: {batch}")
if i == 3:
break
Batch 0: [tensor([[ 3305, 791, 5907, 52686, 58610, 315, 578, 19121],
[58610, 315, 578, 19121, 21785, 315, 12656, 42482]]), tensor([[ 791, 5907, 52686, 58610, 315, 578, 19121, 21785],
[ 315, 578, 19121, 21785, 315, 12656, 42482, 7361]])]
Batch 1: [tensor([[21785, 315, 12656, 42482, 7361, 2028, 35097, 374],
[ 7361, 2028, 35097, 374, 369, 279, 1005, 315]]), tensor([[ 315, 12656, 42482, 7361, 2028, 35097, 374, 369],
[ 2028, 35097, 374, 369, 279, 1005, 315, 5606]])]
Batch 2: [tensor([[ 369, 279, 1005, 315, 5606, 12660, 304, 279],
[ 5606, 12660, 304, 279, 3723, 4273, 323, 198]]), tensor([[ 279, 1005, 315, 5606, 12660, 304, 279, 3723],
[12660, 304, 279, 3723, 4273, 323, 198, 3646]])]
Batch 3: [tensor([[3723, 4273, 323, 198, 3646, 1023, 5596, 315],
[3646, 1023, 5596, 315, 279, 1917, 520, 912]]), tensor([[4273, 323, 198, 3646, 1023, 5596, 315, 279],
[1023, 5596, 315, 279, 1917, 520, 912, 2853]])]
Token and Positional Embeddings for LLMs¶
This cell demonstrates how to combine token embeddings and positional embeddings, which are essential components in transformer-based language models (LLMs) like GPT. Token embeddings represent the meaning of each token, while positional embeddings encode the position of each token in the input sequence, allowing the model to capture word order and context.
What the Code Does¶
- Defines
vocab_sizeandembedding_dim: Sets the vocabulary size and embedding dimension for the model. - Sets
context_length: Specifies the maximum sequence length (context window) the model can process. - Creates Token Embedding Layer: Maps each token ID to a dense vector of size
embedding_dim. - Creates Positional Embedding Layer: Maps each position (from 0 to
context_length - 1) to a dense vector of the same size. - Loads a Batch of Data: Uses the DataLoader to get a batch of input and target token sequences.
- Computes Token Embeddings: Looks up embeddings for each token in the input batch.
- Computes Positional Embeddings: Looks up embeddings for each position in the sequence.
- Combines Embeddings: Adds token and positional embeddings to form the final input embeddings for the model.
- Prints Shapes: Displays the shapes of the resulting tensors to verify correctness.
Tip:
- Adding token and positional embeddings is a standard practice in transformer models, enabling them to understand both content and order of tokens.
- Ensure that
context_lengthmatches the maximum sequence length used during training and inference.
vocab_size = tokenizer.n_vocab
embedding_dim = 512
context_length = 1024
token_embedding_layer = torch.nn.Embedding(vocab_size, embedding_dim)
positional_embedding_layer = torch.nn.Embedding(context_length, embedding_dim)
dataloader = create_dataloader(all_text, batch_size = 8, max_length = context_length, step_size = 512, shuffle = True)
dataiter = iter(dataloader)
test_input, test_targets = next(dataiter)
token_embeddings = token_embedding_layer(test_input)
print(f'Token embeddings shape: {token_embeddings.shape}')
positional_embeddings = positional_embedding_layer(torch.arange(context_length))
print(f'Positional embeddings shape: {positional_embeddings.shape}')
input_embeddings = token_embeddings + positional_embeddings
print(f'Input embeddings shape: {input_embeddings.shape}')
Token embeddings shape: torch.Size([8, 1024, 512]) Positional embeddings shape: torch.Size([1024, 512]) Input embeddings shape: torch.Size([8, 1024, 512])
Leave a Reply